Jay Cordes is a data scientist and co-author of "The Phantom Pattern Problem" and the award-winning book "The 9 Pitfalls of Data Science" with Gary Smith. He earned a degree in Mathematics from Pomona College and more recently received a Master of Information and Data Science (MIDS) degree from UC Berkeley. Jay hopes to improve the public's ability to distinguish truth from nonsense and to guide future data scientists away from the common pitfalls he saw in the corporate world.
Check out his website at jaycordes.com or email him at jjcordes (at) ca.rr.com.
So you’ve decided to invest in mutual funds and you’ve narrowed down the list to some promising candidates. You’ve got your Morningstar ratings handy and you’ve got past performance charts. What can go wrong?
Well, there’s one big problem: there’s basically no evidence that better performing fund managers aren’t just getting lucky. A study by Barras, Scaillet, and Wermers estimated that only 0.6% of over 2000 actively managed domestic equity funds actually demonstrated that skill was involved their long-term performance. Even that number wasn’t statistically significant, so the study could not rule out the possibility that absolutely no one knows how to beat the S&P. Since you’re all experts in regression to the mean now, you know exactly what to expect in the future from a fund whose past returns were entirely due to luck. You may as well pick a fund at random, or better yet, just pick the one with the lowest expense ratio, like an index fund. Actively managed funds appear to be charging for expertise that is primarily (entirely?) an illusion!
So if there’s no skill involved, why does it always look like there are so many mutual funds with great track records? It’s basically survival of the luckiest. The funds that are doing the worst are the most likely to get killed off, so when you’re only shown the survivors, you end up seeing what the victims of that stock-picking mail scam got to see: a history of hits with no visibility into the number of misses.
By the way, past performance shouldn’t cause you to hold onto stocks, either. Many people don’t want to sell stocks that have gone down since they purchased them, reasoning that they’ll eventually go back up and make a profit. A good way to find out if you actually believe the stock is still a good investment, ask yourself “if I didn’t own this stock right now, would I buy it?” If the answer is no, you should recognize that by not selling it, you are effectively doing just that. Whatever happened in the past is a sunk cost; you would either prefer to have the money or the stock.
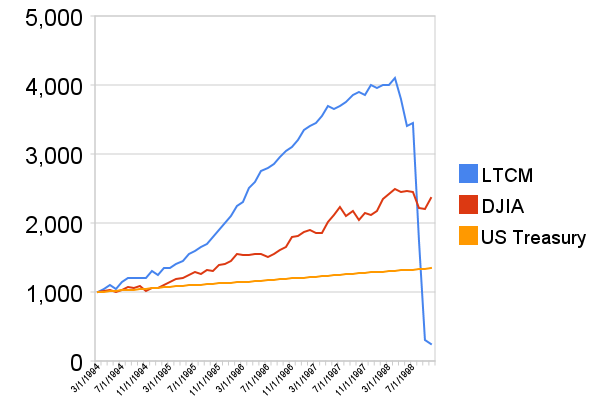
There’s another problem that occurs when you judge investments only on their historical returns. You may find a hedge fund, for example, with huge and stable returns every year and not have any idea that this is coming…
That’s what it would have looked like if you had put $1000 into the top Long-Term Capital Management hedge fund in 1994. If you think that kind of disaster looks like it couldn’t just be the result of good luck finally running out, you’re right; it has to do with financial leverage.
To demonstrate how the illusion of stability can be created through the use of leverage, consider the following simulation I created in Excel assuming a $10k initial investment and nothing better than a coin-flip’s chance at predicting the future. After 13 years, I had demonstrated a completely stable 20% return every year! You’d definitely want in on this fund, right?
Year 1
20%
$ 12,000
Year 2
20%
$ 14,400
Year 3
20%
$ 17,280
Year 4
20%
$ 20,736
Year 5
20%
$ 24,883
Year 6
20%
$ 29,860
Year 7
20%
$ 35,832
Year 8
20%
$ 42,998
Year 9
20%
$ 51,598
Year 10
20%
$ 61,917
Year 11
20%
$ 74,301
Year 12
20%
$ 89,161
Year 13
20%
$ 106,993
You can probably guess that in year 14, it went completely broke. Behind the scenes, I was just following a Martingale strategy where I bet 20% of the money on a coin-flip and, if it didn’t work out, I’d double the size of the bet on another coin flip to make up for it. If that didn’t work out either, I still had 40% of the money left to try to get lucky and recover. If at any point I’d made the right pick and got to a 20% profit, I’d call it a day and wait until the next year to repeat the process. As long as I keep my proprietary trading strategy under lock and key (because it’s obviously so valuable), who’s going to know?
Okay, so forget trying to judge the quality of funds for yourself based on their history, how about using Morningstar ratings instead? Well, it turns out, that would also usually be worse than if you just minimized the expense ratio.
“The star rating is a grade on past performance. It’s an achievement test, not an aptitude test…We never claim that they predict the future.”
Don Phillips, President of Fund Research at Morningstar
At this point, you might be comforting yourself with the fact that you have a financial advisor who knows all of this and can dodge the pitfalls for you and recommend great investments. Unfortunately, unless you are one of the few people who uses a “fee only” advisor, there are probably some serious conflicts of interest that may have transformed your advisor into a salesman. He or she may be quietly extracting commissions of up to 8% for selling you stuff with costs hidden in places you are unlikely to discover.
The moral to the story is: forget about trying to predict the market. Get a “fee only” advisor to help you diversify broadly (into investments with low expense ratios, of course) and with an appropriate amount of risk for your situation, and don’t forget to re-balance every once in awhile. And while you’re at it, quit trying to time the market as well; the time to sell is when you need the money and the time to buy is when you have the money. Get rich slowly.
As a game freak and a data wonk, there are few things more interesting to me than the ongoing battle between man and machine, with popular games serving as the battlefield. For each game, there’s only one time in human history when machines take us down and never look back, and for almost all games, that moment in time is in the recent past. These stories of seemingly unbeatable champions finally meeting their match and conceding defeat give us a glimpse into the unlimited potential for future problem-solving techniques. Welcome to my short history of Man vs. Machine.
Backgammon (1979) – BKG 9.8
When world champion Luigi Villa lost a backgammon match 7-1 to a program by Hans Berliner in 1979, it was the first time that a bot had beaten a world champion in any game. Later analysis of the games showed that the human was actually the stronger player and only lost due to bad luck, but Pandora’s box had been opened. In the 90’s, when neural networks revolutionized the bots, machines had truly reached the level of top humans. TD-Gammon was developed in 1991 and was followed in 1992 by Jellyfish and Snowie. There were no databases of moves and no expert advice given to the machines. They were only taught to track certain features on the board (like the number of consecutive blocking points) and to decide for themselves whether they were meaningful. They played themselves millions of times, following a simple racing strategy at first, but soon learned what maximized wins and began to appropriately value and seek better positions. It’s truly like AI; the bots had taught themselves how to play backgammon!
I asked my friend Art Benjamin (who was the all-time point leader in the American Backgammon Tour at the time) when it became clear that bots were truly superior and he said…
I guess I would say it happened in the mid to late 90s with Jellyfish and then Snowie. Can’t offer an exact date and I can’t think of a specific event. There was a backgammon server called FIBS (First Internet Backgammon Server) that was big in the 90s and the top rated player was Jellyfish. Only later was it revealed that it was a Bot. I think that gave it instant recognition as a force to be reckoned with.
At one of the backgammon tournaments, Art introduced me to Jeremy Bagai, who did something that I think is awesome. He wrote a book that used Snowie to locate and analyze mistakes in the classic strategy guides. He basically took the bibles of backgammon and fixed them, according to what the bots had discovered. How great would it be to have books like that in every field, showing specific cases where objective progress has been made? I think the toughest program out there these days is eXtreme Gammon, so maybe it’s time for another edition of that book that corrects Snowie’s mistakes?
Checkers (1994) – Chinook
In 1989, a team led by Jonathan Schaeffer from the University of Alberta created a computer program that could play checkers called Chinook. In 1990, Chinook was already ready to take its first crack at the world title, but fell short against Marion Tinsley. Tinsley, who is considered the best checkers player of all-time, won 4 games to Chinook’s 2, with 33 draws. In the rematch in 1994, it seemed that Chinook might actually have a chance against the seemingly unbeatable human champion (to give an idea of his dominance, Tinsley won his 1989 world title with a score of 23 draws, 9 wins, and 0 losses!) However, after 6 draws, the match came to an unfortunate and premature end: Tinsley had to concede due to abdominal pains, later diagnosed as cancerous lumps on his pancreas.
Using strategies such as minimax heuristic, depth-first search, and alpha-beta pruning, in combination with an opening database and a set of solved end-games, Chinook held onto its title with a 20-game draw against the #2 player, Don Lafferty, but hadn’t yet truly become unbeatable. During the match, Lafferty broke Chinook’s 149-game unbeaten streak, which I believe earned him the title of “last human to beat a top computer program at checkers.”
After the next match, in 1995, it was official: machine had surpassed man. Don Lafferty fell by a score of 1-0 with 35 draws. A couple years later, Chinook retired after being unbeaten for 3 years. If there were any doubts about whether or not Tinsley would still be able to beat Chinook, those questions were put to rest in 2007 when it was announced that checkers was solved. Schaeffer’s team had done it: they proved that checkers is a draw if both sides play perfectly.
Chess (1997) – Deep Blue
Deep Blue became the first computer program to win a chess game vs. a current world champion when it took a point off of Kasparov on its way to a 4-2 loss in 1996. However, what most people remember is the rematch in 1997, which “Deeper Blue” actually won, 3.5 to 2.5. At one point during the match, the program ran into a bug and played a random move, which unnerved Kasparov, since he was familiar enough with computer strategies to know that no machine would have selected the move. Under huge psychological pressure and suspicion that the other team was cheating, Kasparov blundered away the match against the IBM behemoth, which was capable of evaluating 200 million positions per second.
Several matches followed between human champions and top computer programs that resulted in draws, so computer superiority in chess wasn’t actually clearly established until 2005, when Hydra was unleashed on the world. It dispatched 7th-ranked Michael Adams by a brutal score of 5.5 to 0.5. 2005 may also be the year that goes down in history as the last time a human beat a top machine in tournament play (Ruslan Ponomariov). As of 2008, it was still true that humans playing alongside computers (“centaurs”) were superior to bots playing by themselves, but these days, it looks like even that is no longer the case. The top commercial chess programs available today include Komodo, Houdini, and Rybka and they are continuing to improve, leaving humans far behind.
Chess may never be solved like checkers was, but impressive progress has been made on the endgame, which has now been solved for 7 pieces or less on the board. Similar to the insights in Jeremy Bagai’s backgammon book, there are endgames that were presumed to be draws for many years that turn out to be wins if played perfectly, in one case only if over 500 perfect moves are played (good luck learning that one!) I love this quote from Tim Krabbe about his experience with these solved endgames:
The moves are beyond comprehension. A grandmaster wouldn’t be better at these endgames than someone who had learned chess yesterday. It’s a sort of chess that has nothing to do with chess, a chess that we could never have imagined without computers. The Stiller moves are awesome, almost scary, because you know they are the truth, God’s Algorithm – it’s like being revealed the Meaning of Life, but you don’t understand a word.
Othello (1997) – Logistello
This story is short and sweet. Computer scientist Michael Buro started developing an Othello-playing bot called Logistello in 1991 and retired it seven years later, after it dispatched the world champion Takeshi Murakami by a score of 6-0. Othello is so popular in Japan, 9 television stations covered the event. Afterwards, Murakami said “I don’t think I made any mistakes in the last game. I believed I could win until the end.”
Scrabble (2006) – Quackle
The next human champion to fall to a computer in his respective game was David Boys. Boys, the 1995 world champion, had qualified for the honor to face the machine by beating out around 100 humans in an 18-round match. He looked like he would send the machine back for another development cycle after winning the first 2 rounds, but Quackle didn’t crack under the pressure and won the remaining games to take the match 3-2. As usual, beating the world champion wasn’t enough for the game freaks of the world; Mark Richards and Eyal Amir took things to the next level by building a bot that takes into account the opponent’s plays to predict what tiles are in his rack. It then selects moves that block high-scoring opportunities the opponent might have, proving that AI truly is ultimately evil.
Jeopardy (2011) – Watson
In 2011, IBM was back in the business of high-profile man vs. machine matches when it created Watson and took down two of the best all-time Jeopardy champions. In the end, it had a higher score than both humans put together and, as with Deep Blue, the machine itself was a beast: 2,880 parallel processors, each cranking out 33 billion operations per second, and had 16 terabytes of RAM. Despite some humorous mistakes, such as the time it considered milk to be a non-dairy powdered creamer, Watson’s victory strikes me as the most impressive in this list. The difficulty in developing a system able to interpret natural language and deal with puns and riddles and come up with correct answers in seconds (searching the equivalent of a million books per second) is off the charts. We’re in the world of Sci-Fi, folks.
Poker (2015?) – PokerSnowie?
I’m going out on a limb here and predicting that poker is the next game to fall to the bots and that the moment is just about here. Being a game of imperfect information, poker has been particularly resistant to the approaches that were so successful for games such as backgammon, in which the machine taught itself how to play. An optimal poker strategy generated this way tends to include betting patterns that an experienced player can recognize and exploit.
By the turn of the century, pokerbots had gotten pretty good at Limit Hold ‘Em (eventually winning a high-profile heads-up game against professionals), but the more popular variation, No Limit Hold ‘Em remained elusive. The University of Alberta made the first significant step in changing that when they planned to hold the first-ever No Limit category in their Poker Bot competition at the 2007 Association for the Advancement of Artificial Intelligence (AAAI) conference. Coincidentally, shortly after this was announced, a friend of a friend named Teppo Salonen, who had won 2nd place the prior year in the limit competition, came up to my house for a game. I joined others in pestering him to enter the no-limit category, since the competition would never be softer (if it’s possible to consider competition offered by universities such as Carnegie Mellon and the University of Alberta to be “soft”). I knew a thing or two about beating bots at poker, since I had downloaded and beat up on the best bots that were available at the time, so Teppo invited me to serve as his strategic advisor and sparring partner. Months later, after many iterations, (and after Teppo overcame a last-minute technical scare) BluffBot was ready to go and entered the competition. And WON. What we had done didn’t really sink in until I read the response from one of the researchers who were blind-sided by Bluffbot:
They are going up against top-notch universities that are doing cutting-edge research in this area, so it was very impressive that they were not only competitive, but they won… A lot of universities are wondering, “What did they do, and how can we learn from it?”
The following year, the world once again made sense again as the University of Alberta team took the title. Things were pretty quiet for a few years until mid 2013, when PokerSnowie hit the market. As a former backgammon player, seeing the name “Snowie” in the title got my attention, so I was one of the first to buy it and enter the “Challenge PokerSnowie” to establish its playing strength. PokerSnowie categorizes its opponents based on their error rates and was handily beating every class of opponent with the sole exception of “World Class” players Heads Up. I was one of the few who managed to eek out a victory over it (minimum of 5,000 hands played), but could tell that it was significantly stronger than any other bots I’d played against. It was recently announced that the AI has been upgraded, and I suspect that it may be enough to push the bot out of my reach and possibly anyone else’s.
It appears that it’s time for a 5,000 hand rematch against the new AI to find out if it has passed me up as I suspect it has. I’ll periodically post my results and let you know if, at least for a little longer, the poker machines can still be held at bay. See results below!
http://xkcd.com/1002/
Round 1 of 10: after 500 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$580.50 (+$1.16 per hand)
Error Rate: 7.15 (“world class”)
Blunders: 13
Notes: I’m on a huge card rush, prepare for regression to the mean.
Round 2 of 10: after 1000 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$609.00 (+$0.61 per hand)
Error Rate: 7.51 (“world class”)
Blunders: 25
Notes: I extended my lead a bit, but not surprisingly, my winrate did regress towards zero. My error rate also crept higher (despite one fewer “blunder”) and pushed me closer to the threshold for “expert”, which is 8. I’m including the error rates so that if Snowie makes a sudden comeback, it should be clear whether or not it was due to the quality of my play suddenly taking a turn for the worse or Snowie finally getting some cards.
Round 3 of 10: after 1500 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$322.00 (+$0.21 per hand)
Error Rate: 7.19 (“world class”)
Blunders: 31
Notes: PokerSnowie took a big bite out of my lead in round 3 despite a drop in my error rate as well as my blunder rate (only 6 in the last 500 hands). As the Swedish proverb says: “luck doesn’t give, it only lends.”
Round 4 of 10: after 2000 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$362.50 (+$0.18 per hand)
Error Rate: 7.49 (“world class”)
Blunders: 42
Notes: Despite making a slight profit in the last 500 hands, my error rate increased and my average winnings per hand has continued to drop. The match is still a statistical dead heat.
Round 5 of 10: after 2500 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$497.50 (+$0.20 per hand)
Error Rate: 7.51 (“world class”)
Blunders: 49
Notes: My error rate crept slightly higher, but I was able to raise my winnings per hand for the first time. Snowie’s going to have to catch some cards in the last half of the match to get that $500 back.
Round 6 of 10: after 3000 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$40 (+$0.01 per hand)
Error Rate: 7.55 (“world class”)
Blunders: 62
Notes: Wow, what a difference a round of 500 hands can make! Practically my entire lead was wiped out, despite only a slight uptick in my error rate. Just as I was starting to write Snowie off as too passive, it handed me a nice beating. With four rounds left, the match is truly up for grabs.
Round 7 of 10: after 3500 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
PokerSnowie +$29.50 (+$0.01 per hand)
Error Rate: 7.88 (“world class”)
Blunders: 72
Notes: Snowie took the lead for the first time in the match, but I’m glad not to be losing by much more. I was down $400 until about 100 hands ago, but after betting a few big draws that hit, I almost pulled back to even. More concerning is the fact that my error rate increased by a big amount this round, almost demoting me to “expert” status. It turns out my biggest blunder led to one of my biggest pots: Snowie says I made a huge mistake betting my small flush on the turn instead of checking. The outcome was great, however, since Snowie happened to hit a set (pocket pair that matched a card on the board) and check-raised me all-in. I called and my flush held up. The last card was a scary fourth heart, so I doubt I would have gotten as much from the hand if I had checked. I’m not sure why PokerSnowie was so sure betting my flush was a mistake (maybe to control the size of the pot in case my flush was already behind or got counterfeited on the river?) Could be a sign PokerSnowie knows something I don’t.
Round 8 of 10: after 4000 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$583 (+$0.15 per hand)
Error Rate: 7.99 (“world class”)
Blunders: 82
Notes: I hit back with a rush of cards and had my best round so far (in terms of results). Unfortunately, my error rate crept higher again, putting me at the border between “world class” and “expert” in PokerSnowie’s eyes. I would hate for the program to lose respect for me, so I’m going to have to start making better decisions. Of course, PokerSnowie could just be punishing me, since one of my biggest “errors” was calling its pot-sized all-in on the river with one measly pair. It turned out that I caught PokerSnowie bluffing and won $234 on the hand.
Round 9 of 10: after 4500 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$869.50 (+$0.19 per hand)
Error Rate: 7.85 (“world class”)
Blunders: 85
Notes: Only 3 blunders this time and I extended my lead. It’s looking bad for PokerSnowie, as it will need an epic rush in the last 500 hands to pull out the match.
Round 10 of 10: after 5000 hands (0.5/1.0 blinds, 100 BB buy-in cash game, with auto-rebuy at 70%)…
Jay +$1749 (+$0.35 per hand)
Error Rate: 8.03 (“expert”)
Blunders: 100
Notes: When I posted an “epic rush” would be necessary for PokerSnowie to win, I didn’t actually believe it was possible for $870 to change hands between us in the last 500 hands with $0.50/$1 blinds. Incredibly, it happened, although in my favor. I hit practically every draw and if I didn’t know any better, I’d say the machine went on tilt, as it repeatedly bluffed off its chips like it was a fire sale. The program did get some revenge, however, by demoting my rating into the “expert” range by crediting me with 15 blunders during this round. Let’s look at a few of the big ones:
1. I raised to $3 with QJ on the button and Snowie re-raised to $9. I called and my QJ became the best possible hand when the flop came 89T rainbow (no two cards matching suits). Snowie bet $9 and I only called, reasoning that I didn’t have to worry about any flush draws (and also couldn’t represent them). I also didn’t want to end the fire sale if Snowie was going to keep bluffing at pots. My decision was tagged by Snowie as a huge error. Then, on the turn, a completely harmless offsuit 2 came. Snowie bet again, this time $18, and again I only called for the same reasons. This was also flagged as a major blunder. The river brought another 2, and Snowie continued with a bet of $72. I conservatively called, thinking that an all-in for its last $77.50 here might only get called by a full house (Snowie finally liked my decision, although it said to mix in an all-in 4% of the time). It turns out that Snowie had AA (was evidently value-betting and assuming that I would continue calling with only a pair?) and lost the $216 pot.
2. Snowie raised to $3 pre-flop and I called with K8. The flop came 83T, all diamonds, which was great, since I had 2nd pair and my King was a diamond. I checked, hoping Snowie would continuation bet, but Snowie checked as well. The turn card was a 9 of hearts and I bet $3, which Snowie called. The river card was a 9 of diamonds, giving me the flush, but also pairing the board. I bet $6 and Snowie raised with a huge overbet of $54. It was certainly possible that it was trying to get value for its full house or ace-high flush, but it just didn’t smell right. If it had the ace of diamonds, why hadn’t it bet on the flop or raised on the turn to build a pot? And with a paired board, what would it do if I re-raised its huge overbet on the river? On the other hand, if it had flopped a set (which turned into a full house on the river to justify the huge bet), would it really have checked on the flop and only called on the turn and not made me pay to see a fourth diamond appear? Anyways, I called its bet and won the $120 pot when it flipped over J9 for three of a kind, which it had decided to turn into a massive bluff-raise. Fire sale! Snowie labeled my call as a huge blunder (ranking the king-high flush’s showdown strength as only a 0.59 out of 2.00).
3. In this hand, I had AK on the button and raised to $3. Snowie re-raised to $9, which I re-re-raised to $18. Snowie re-re-re-raised to $54 and I called. Snowie flagged my call as a huge mistake, saying I should have raised yet again. The flop came 658 with two clubs we both checked. The turn brought a third club and Snowie bet $54 and I folded. Evidently, it had a wider range than I imagined with all of that pre-flop raising, as it turned out to only have a KQ (with the king of clubs) which it had turned into a semi-bluff on the turn to take the pot. I can’t say I’ve seen many people 5-bet before the flop with King-high, so I’m still not sure about the “6-bet with AK” idea.
I’m happy to have defended humanity’s honor once again, but my confidence that PokerSnowie will take over the world was shaken a bit by its performance. If the “fire sale” strategy is a big part of its gameplan, it may still be a few years and AI upgrades before it can take down a top human.
So I lied. Regression to the mean isn’t everywhere. If something is measured or tested and has no element of chance involved, it will remain consistent. For example, if you’re repeatedly measuring people’s shoe sizes or heights. Unlike hair, you don’t really have a “bad height day.” (However, as a challenge to see if you’ve really grokked the previous blog entries, see if you can explain why children of really tall parents don’t usually match their height, despite the fact that people are generally getting taller.) What I’m getting at is that regression to the mean is directly related to the amount of luck involved in the initial result or measurement.
This means that you’ll see the greatest amount of regression when the measured outcome was completely due to luck. Unfortunately, you cannot tell if this is the case by looking at the stats alone. You can only suspect it because the result was surprising, was from one of a large number of experiments (data-mining), or was from a test that was re-run many times.
By the way, before I continue, for those of you who are hoping I bring up “informative priors” or eventually will discuss R, Python, or Hadoop, let me state for the record that I intend for this blog to be interesting to general readers and is therefore decidedly non-wonky. If you’re looking into a career in data science and want a good overview of the technical skill-set you should develop, allow me to refer you to a great slideshow on the topic by my friend and professor at USC, Saty Raghavachary.
Okay, so when you should you be a skeptic and raise your eyebrows at a test result? Consider this case study: we experimented with four different colors of the same landing page on our parked domains. After a few weeks, it was determined that there was no significant difference between the landers in terms of revenue per visitor. However, at the meeting when this conclusion was reported, our boss then asked “well, what if we look at the results by country?” I disapprovingly shook my head, knowing that I was witnessing a data foul in action. Sure enough, the testing analyst dug into the data and found that…
England prefers the teal lander!
At this point, eyebrows should go up. First of all, we didn’t run the test to find out what England’s favorite colored lander is. This might seem like a nit-pick, since we ran the test and happen to have results for England, but basically, there’s no reason to think that England is any different than any other country in terms of color preference. So there should be a check-mark by the “surprising result” category. Also, for the aggregate result to be break-even, there must be an “anti-England” country or countries out there who hate teal enough to offset them.
Any other “data fouls” here? Yes: this result is one of a large number of experiments and therefore needs to be validated. Even though we only ran one test, by breaking down the results by country, we effectively turned one test into a hundred tests. That matters, because when you determine “significance” at the 0.05 level, you’re basically saying that 5 times out of a hundred, you will see a random result that looks identical to this. So, how can you tell if this wasn’t one of those five cases?
I convinced my co-workers that data fouls were being committed, so we chose not to roll-out our new teal variation in England until we saw further evidence. Sure enough, the results suddenly reversed, to the point that teal was significantly worse than our standard color in England over the next few weeks.
A great illustration of this concept is the story of the stock-picker mail scam: A scammer sends out a letter to 1024 people, he tells 512 of them that a stock is going to go up that month and he tells the other half that it’s going to go down. The next month, he only continues writing to the 512 to whom he gave the correct prediction. He tells 256 of them that the stock will go up this time and 256 of them that it will go down. He repeats the same thing the next couple months for 128 of them and then 64. After that, for 32 people, they have received a correct stock prediction every month for the last 5 months. The chances of flipping heads 5 times in a row is 3.125%, so this would satisfy the 0.05 confidence level if any of them happen to be data wonks! Of course, that last letter states that if they want to continue getting the stock picks, they need to pony up some cash. As the recipient of the letter, if you have no evidence of anyone getting incorrect picks, you can’t just do the math to determine if the scammer actually can predict the future of that stock. Sometimes you just need a Spidey Sense in order to suspect that a data foul has been committed.
This is actually a recurring problem with science publishing these days. There’s a phenomenon called “truth decay” which refers to the fact that many studies are published and then are likely to be contradicted by future studies. Part of the reason for this is that interesting studies are the ones that are more likely to be published, which usually means that they’re surprising and and are therefore less likely to be true (and no, I’m not going to use the words “informative prior”!) There may be many previous experiments that showed the opposite result that weren’t published because they only confirmed what people already believed to be true. What’s noteworthy about that? Even worse, an experimenter can repeat an experiment or data-mine in private and present the result as if no data fouls were committed! It’s important to know whether they tortured their data in order to get desired results.
Sometimes, problems can occur simply because many independent scientists have an interest in answering the same question. If one of them finds a concerning result that the others didn’t find, guess which study you’re going to hear about? An example that drives me crazy is the controversy about aspartame, “one of the most thoroughly tested and studied food additives [the FDA] has ever approved.” In addition to the fact that there’s a body of evidence showing that it’s perfectly safe, remember that it’s replacing sugar, which isn’t exactly a health food. These types of situations put scientists in a tough spot, because science never says “okay, we’re 100% sure it’s fine now.” However, from a practical point of view, people should at some point should accept the consensus and worry about other things, like texting and driving. In fact, there’s probably someone out there behind the wheel right now texting to their friend about how dangerous aspartame is and that they should be sucking down 150 calories of liquefied sugar instead. When someone digs the cell-phone out of the wreckage, it will have this sentence still waiting to be sent: “NutraSweet has only been around since 1965, they don’t know what happens after FIFTY…”
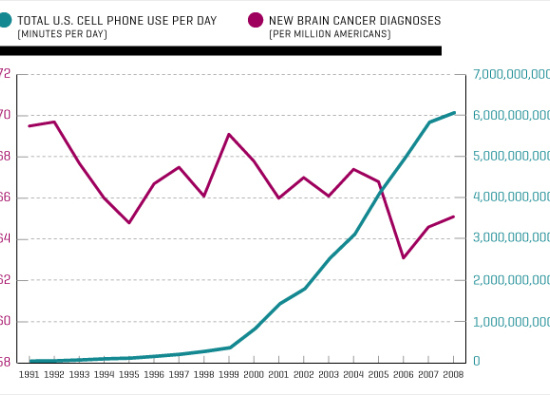
Another fear that seems to live forever is the idea that cell phone usage causes brain cancer. Despite the fact that any physicist can tell you that radiation of that frequency is non-ionizing and therefore has no known mechanism by which it can harm you, public fear drives scientists to test and re-test and re-test until one of them eventually finds that there may be a concern, which drives more fear and more studies! It seems like a harmless endeavor to simply run experiments, but the problem arises when there are so many studies that the usual standards of significance do not imply meaningfulness of results. If you’re still worried about stuff like this, I think it helps to suppose there is a risk and then imagine what the impact would be in the world. I’m pretty sure you’re not thinking it would look like this chart from the link above…
Until there’s a worldwide spike in brain cancer, I just don’t see the point in worrying about this.
Once, when I hesitated to unleash an automated optimization program across the network without first doing a controlled test, my boss asked “What are you saying? It’s not going to find significance?” and I quipped “oh, it will find significance. It just won’t be significant.”
In last week’s post below, I talked about the “Sophomore Slump” and why top performers can rarely keep performing at the same level. I also mentioned that for similar reasons, the worst performers generally improve. To demonstrate this statistical phenomenon, I highlighted the bottom 5 NBA players (in terms of their year-to-date average Fantasy Points per Minute – FPPM) on my fantasy basketball site, with the prediction that they would improve this week. Well, let’s check in on them this week and see how the experiment turned out!
Mike Miller (CLE) – went from 0.23 to 0.34.
Nik Stauskas (SAC) – 0.29 to 0.50. This guy took off with back-to-back games with an average of one fantasy point per minute. He had 9 points, 3 rebounds, and 2 blocks in a game.
Will Barton (POR) – 0.35 to 0.54. He crushed it in his last game with a 1.67 FPPM.
Alan Anderson (BKL) – 0.36 to 0.51. 12 points in his last game.
Jason Maxiell (CHA) – 0.37 to 0.50 for the year. Had an 8 point, 6 rebound game.
The “loser lift” prediction goes five for five! Every one of these guys dramatically increased their season’s average fantasy points per minute immediately after I called them out as being in the bottom five. Maybe they read my blog and played harder. Or more likely, this is just another example of the common statistical phenomenon called regression to the mean. Since this tendency for the worst to improve is fairly obscure, there are many times when people mistake it as evidence that something they did caused the improvement.
This exact situation happened a few years ago at work. A friend was tasked with optimizing under-performing domain names for our customers. He was pretty savvy with stats and suspected that he wasn’t doing anything useful, but every time he touched those domains, they jumped up in revenue! One day, he forgot to make any changes, and the revenue for the names jumped up just like it always did. The customer said “well, whatever you did worked!” At that point, it really hit home that he could be unintentionally hurting revenue (without a random control group, how would you know?) and he stopped doing it.
I also once played a practical joke on the guys at work by identifying domain names that had very low revenue for a long time and then claiming that I was “activating” them by clicking images on each of the web pages. When they saw the revenue increase by 400%, people were scrambling to figure out how they could scale it up and hire temps to do the clicking. Thankfully one of them eventually said “I think Jay’s messing with us” and kept people from wasting too much time (I probably shouldn’t have punked them on a day when I was out of the office, but I thought the story was ridiculous enough that they wouldn’t fall for it). Hopefully, the joke left a lasting impression and taught everyone to be more skeptical and to request a control when faced with claims of incredible revenue increases.
Once you’re familiar with this idea that the best things tend to decline and the worst things tend to improve, you will see it everywhere. One place I thought it would show up was in the odds for UFC fights. A few years ago, I started an experiment and bet (fake money!) on the biggest underdog for each UFC event at mmaplayground.com. So far, after 160 events, my play money winnings for those bets stands at +$11,417.
The reason this works is because I think this site (since it’s not concerned with making a profit on the bets) is posting what they believe are the true odds for each fight (real money sites appear to underpay for big underdogs, so please do not take this as an endorsement to gamble away all of your money!) Since they were more likely to have underestimated the biggest underdogs and overestimated the abilities of the biggest favorites, the odds they came up with for those fighters were favorable for me. The average money odds posted for the big underdogs was 613, which implies a winning percentage of only 14%. The actual win probability for them was 30 / 160 = 18.8%. This doesn’t necessarily mean that the site is being generous when it comes to posting odds for underdogs; they may have perfectly estimated the odds based on past performance. It’s just that the worst fighters are in the same situation as our five NBA players above: probably not living up to their true abilities.
What is the “sophomore slump” and the “Sports Illustrated curse” and are they real or just superstitions?
The sophomore slump is when the top rookies in some sport usually perform worse in their second year. Similarly, the Sports Illustrated curse is when an excellent player is recognized on the cover of SI and then suffers a decline in accomplishments soon afterwards. It turns out that these phenomena are very real and have nothing to do with players being psychologically affected by public recognition. You might think that players could avoid the curse if they never learn that they’re on the cover of Sports Illustrated, but it turns out that they’re pretty doomed anyway. So what causes this?
We data wonks are very familiar with this phenomenon of Regression to the Mean and see it everywhere. We see it when sequels to great movies don’t live up to the originals. We think of it when people try to tell us that punishment for bad behavior works better than reward for good behavior. We nod with understanding when we are told to rebalance our investment portfolios. We cringe when people tell us how they made a tweak to their under-performing websites and the improvement was immediate and dramatic.
What it basically boils down to is this: those who performed badly were more likely to have had a bad day (or week or year) and those who performed well are more likely to have gotten somewhat lucky. It seems obvious when stated like that; after all, how often were the worst performers lucky to do as well as they did? However, the results that follow from this truth can be subtle and surprising.
If you tell a scientist that you felt like you were on your deathbed, took a pill, and then woke up the next day feeling better, he or she will not accept that as evidence that the pill worked. They’ll say “you need a control” and a bunch of other wonky stuff that you think doesn’t matter because how clear and obvious could it be? Well, their objection isn’t only that unless you’re actually dying, you’ll generally improve on your own, it’s also that having your worst day ever is an unusual event and is hard to repeat. Like Seinfeld, you probably have the strange sensation that all your bad days and good days even out. What is really happening is that your fantastic days are almost always better than the days after them and your horrible days are almost always worse.
What is less commonly known than the sophomore slump is the opposite situation: let’s call it the “losers lift.” To demonstrate this, let’s do an experiment. I just looked at the stats in my fantasy basketball league (shout-out to basketball.sports.ws) in an unusual way… from the bottom up. Ranked by fantasy points per minute, as of 11/21, here are the WORST five players in the NBA right now (who’ve played at least 10 games so far)…
Mike Miller (CLE) – 0.23
Nik Stauskas (SAC) – 0.29
Will Barton (POR) – 0.35
Alan Anderson (BKL) – 0.36
Jason Maxiell (CHA) – 0.37
I predict that over the next week, most or all of these players will improve (assuming that I use my data wonk magic and give their basketball cards a pep talk, of course). I’ll follow up in a week and let you know what happened.
In the meantime, rebalance those portfolios, lower your expectations for sequels, go ahead and reward your kids for good test scores, and for God’s sake, use a control (random untreated group) if you’re trying to determine if something works! Also, I’m sorry to tell you that if you really enjoyed this post, the next one probably won’t be as interesting to you.