Did you miss my rousing keynote at the Claremont Data Science conference? You’re in luck! Below are my slides, and every somewhat witty and thought-provoking thing I said…

Hi, I’m Jay. I’m super excited to be here, especially because this is the first time I’ve ever done a talk like this! My friend told me that this experience would be good for my next book, the 9 pitfalls of public speaking. Funny guy! My co-author Gary is sitting over there. You do know he’s the one with a PhD from Yale, right? You had a 50/50 shot at hearing from a genius today! Don’t worry, though, I’m not a total clown. I graduated from Pomona College with a degree in math and worked as a software developer for 11 years before following my inner data-wonk to the Analytics department of a booming Internet company. I would take the Metrolink from Claremont to downtown L.A. every day and those years of grand successes and epic failures taught me the value of scientific rigor.

I had a manager once who liked to say “up is up”, which I took as meaning that data speaks for itself. I strongly disagree. Data needs an interpreter. One who knows things. And machines don’t know anything. They’ll crunch random data and find statistical significance everywhere.
On top of that, as you can see here, it’s not even always clear what “up” is! We had all the data you could ever want at my work. Billions of rows piled into a Netezza database. So we tried to use that wealth of data to answer a simple question: what’s more profitable: 1-click pages or 2-click pages? The answer we got back is that overall, 2-click pages are better. Then we asked, okay, what about in the U.S.? One-clicks are better there. How about outside of the U.S.? One-clicks are better there too. Which “up” are we supposed to believe? This is Simpson’s Paradox in all of its glory. In this case, the weighted average looks like that because we had U.S. traffic mostly on 2-clicks and International traffic mostly on 1-clicks. It’s even worse than that! The reason most U.S. traffic was on 2-clicks was because we had run randomized A/B tests that showed 2-clicks are better here, so even that top line is backwards! We decided to stick with the experiments so we don’t get fooled by confounding variables.
Data science is often said to be about extracting knowledge from data. Well, as you can see from this example, if you’re talking about historical data as opposed to data produced by an A/B test, you need to be very careful to ensure that what you’ve extracted is knowledge and not nonsense. Data science is less about extracting knowledge than creating useful data that can provide knowledge. Up is definitely not always up.

I hope to convince you today that for data science to work, you need to work like a scientist.
When people talk about what data scientists do, they always mention statistics and computer programming and also might say how important it is to have domain or subject knowledge. What they tend to forget is the “science” part. I’m here to tell you that the scientific mindset: the critical thinking, the skepticism, the willingness to put your predictions to the test, and make sure you’re not fooling yourself, is essential.

Rather than just go through all the pitfalls of data science, I’d like to talk about four ways that a scientific mindset can avoid them. (1) You can effectively interpret data (does it mean what you think it means?) (2) You can identify which features might be useful for making predictions. Machines can’t really do that for you because if you include too many nonsense variables, they crowd out the real ones. (3) You’ll be able to evaluate evidence and develop a Spidey Sense and avoid being fooled by the “silent evidence of failures”. Are you seeing the whole picture or is someone showing you the statistical hits and hiding the misses? The last one is that you run experiments whenever possible, because it’s the strongest evidence out there.
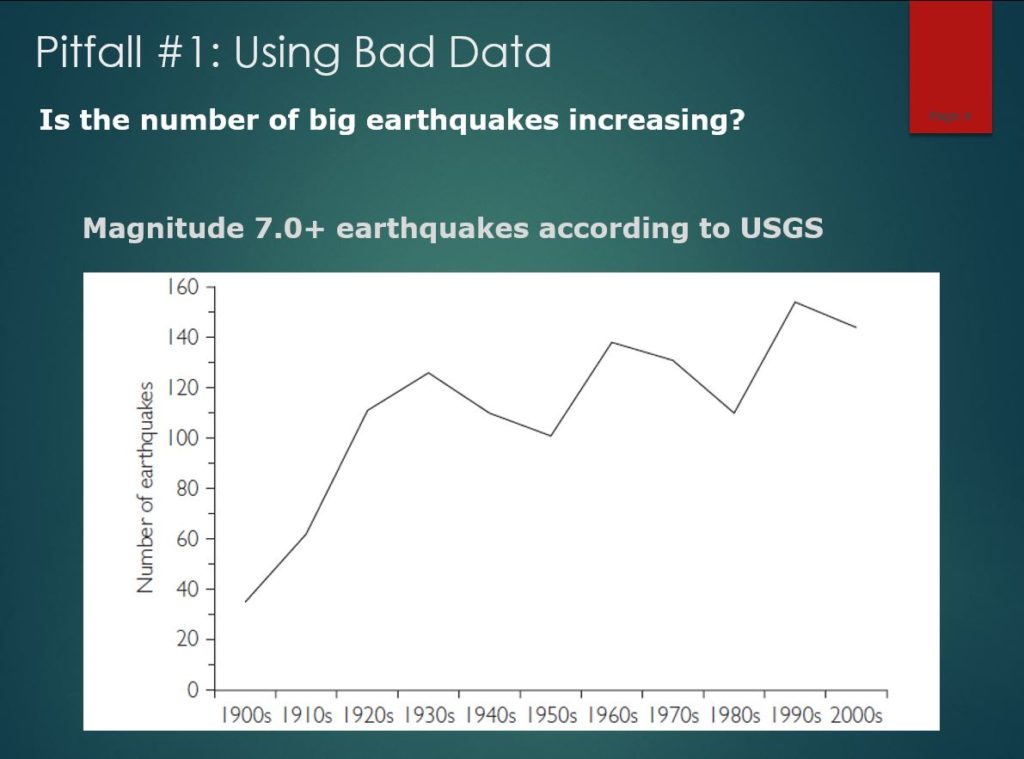
Okay, so let’s put your critical thinking to the test. What’s this data saying? This is earthquake data from the United States Geological Survey showing an alarming increase in the number of major earthquakes worldwide over the last century. Is the apocalypse approaching? Is the earth breaking apart? Or is something wrong with this data?

Don’t worry. These are the earthquakes that were recorded each year, not the number that occurred. There is now a far more extensive network of seismometers than in the past, so many earthquakes that went unnoticed decades ago now get monitored and logged.
If the data tells you something crazy, there’s a good chance you would be crazy to believe it.
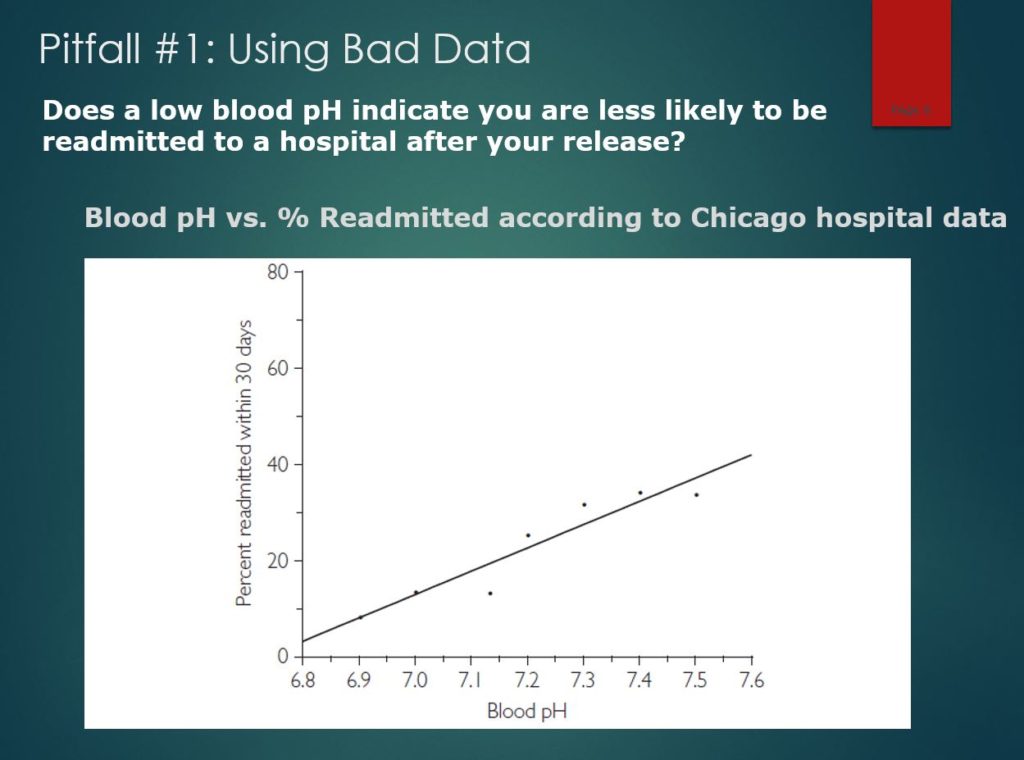
Too easy? Give this one a shot. At Berkeley, I was on a group that analyzed data for over 7,000 patients with sepsis at a Chicago hospital to find a way to predict the chances of being readmitted to the hospital after being discharged. You can see here that we found a strong relationship between the pH level of the patient’s blood (normally between 7.35 to 7.45) to the hospital readmission rates.
There is a clear positive relationship, indicating that patients with high pH levels are more likely to return to the hospital soon after being discharged. A low pH signals that a discharged patient is unlikely to be readmitted. The correlation is 0.96 and data clowns would call it a day. “Up is up”!
However, my teammates and I were not clowns, so we made sure to run this by a doctor to see if it made sense. When he saw this figure, a puzzled look came across his face: “That’s strange; the relationship is backwards. If you have a low pH level, you’re probably dead,” but the chart implied that having a very low pH level was a sign of health. This stumped us until we realized that the data included patients who died during their hospital stay! We had simply found that the patients least likely to be readmitted are the ones who were discharged to the mortuary.
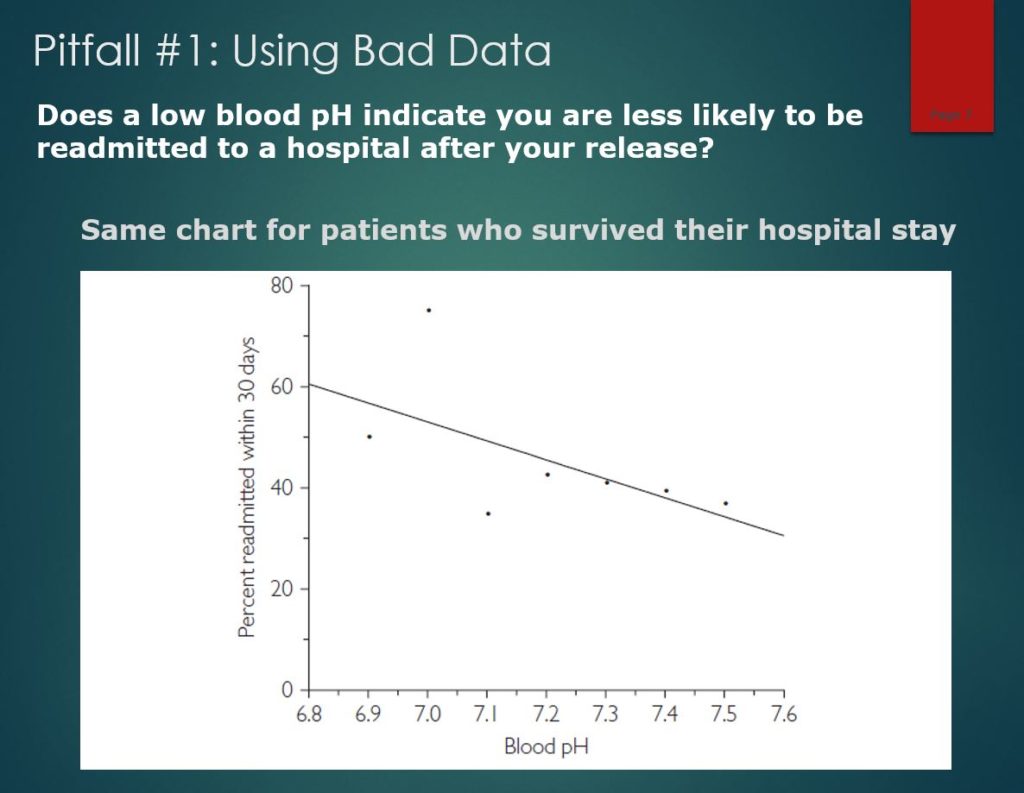
This figure shows that, once we removed the deceased patients, the pattern reversed. Now there is a negative relationship, just as the doctor expected.
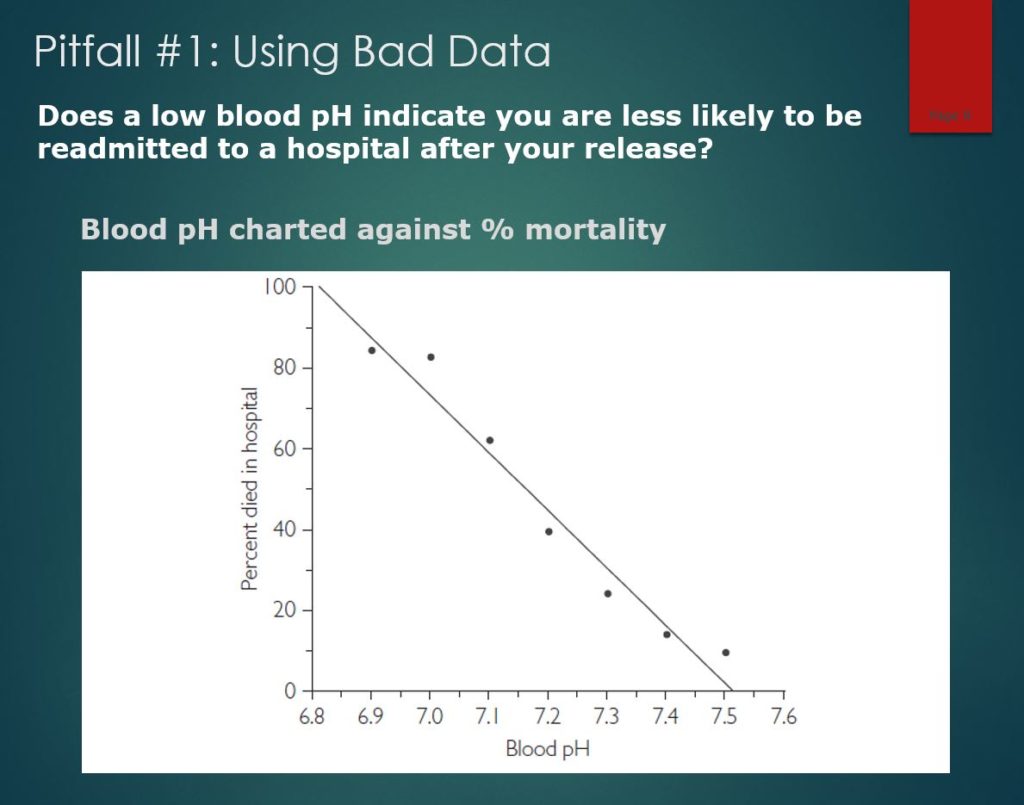
This one shows the clear danger of acidic blood by comparing pH level with the likelihood of death. Patients with pH values below 7.2 are not in good health, they are in serious danger. In this case, the data spoke, but it was talking about something else.
In this case, only the scientific mindset saved us from embarrassment.

It gets even trickier. How can you dismiss patterns that repeat consistently? After Oklahoma won 47 straight college football games, Sports Illustrated ran a 1957 cover story proclaiming, “Why Oklahoma is Unbeatable.” Oklahoma lost its next game and people started noticing that other athletes or teams who appear on the cover of Sports Illustrated tend to perform worse afterward. The Sport’s Illustrated Jinx was born. More recently, we have the Madden Curse, which says that the football player whose picture appears on the cover of Madden NFL, a football video game, will not perform as well the next season. The Sports Illustrated jinx and the Madden Curse are extreme examples of regression toward the mean. When a player or team does something exceptional enough to earn a place on the cover of Sports Illustrated or Madden NFL, there is essentially nowhere to go but down. To the extent luck plays a role in athletic success, the player or team that stands above all the rest almost certainly benefited from good luck—good health, fortunate bounces, and questionable officiating. Good luck cannot be counted on to continue indefinitely, and neither can exceptional success. There’s a Swedish proverb which states “Luck doesn’t give, it only lends.”

We ran into this at work. My company specialized in maximizing profit for domainers, or people who collect websites in order to show ads. We designed and conducted experiments to find the best design. So for example, a web visitor comes in and we generate a random number to determine which page they go to. When we then compared how the various pages performed, we knew we could trust the results because no possible confounding variable could be correlated with a random number. If we had just used a different layout each day, the results might be muddled by the nature of web traffic on the different days—for instance, people are typically more likely to click on ads on a Monday than over the weekend. So anyway, we know what the most profitable design was and used it all over the place.
Anyway, our customers have collections of domain names and, of course, some names do better than others. Some would ask us to work on their “underperformers” and see if we could get revenue up. So my friend in Analytics would change the web page design or the keywords and every single time, revenue would go up by 20% the next day. He was a hero and they were like “you should do this full time!” We made the point that, to be scientifically rigorous, we should really only be working on a random half of the names in order to have a control for comparison, but they thought we were being ridiculous. A twenty percent revenue lift the day after he made changes and we’re nitpicking the process?
Well, one day he forgot to make the changes and the next day, revenue went up for the names by 20% like they always did. It was like an anti-jinx! Instead of the best performers getting on the cover of Sports Illustrated, this was the worst performers getting emailed to Analytics. Someone came by his desk to congratulate him again and he said “I didn’t get around to it yet” and they said “well, whatever you did worked!” Now, we knew for sure that we had to hold back a control, because there was no way to know if what he was doing was helping or hurting!
It turns out that Regression toward the Mean is everywhere. Let’s quickly go through a few more examples…
Why is there a sophomore slump? It’s because you’re looking at the best freshmen. Whether you’re looking at the best batting averages or any other statistic, the top performers will almost always do worse the next time.
Why are movie sequels typically worse than the originals? Well, if you’ve been paying attention, you know how to fix this one. If you want sequels that are better than the originals, make sequels to the worst movies!
Why does punishment seem to work better than reward? Johnny does something exceptionally well and you give him a treat. Then, he does worse. Johnny does something exceptionally badly and you whack him. Then, he does better. The same thing would have happened without the treats or the whacking.
There was a study showing that kids who underperformed on the SAT did better the next time if they were on a drug called propranalol to relax them. As soon as you heard, “underperformed”, I hope your Spidey Sense tingled. They’re expected to do better if they underperformed! The kids almost certainly did worse on the drug than they would have without it, but you’d never know, because they didn’t use a randomized control.
Now, to be clear, this is not the even-steven theory from Seinfeld. Your luck will not reverse, you will just become less lucky.
So you can see why people believe in jinxes! By the way, if you think this talk is exceptionally interesting right now, I have bad news about the rest of the presentation (I knock on wood).

So interpreting data requires the scientific mindset, but what about finding good predictive features? Here’s a tough one for you. What is this thing?

Did anyone get it? Of course! This is easy for humans. Even if the sign were bent, rusty, or has a peace sticker on it, we would still know what it is. Not so with image-recognition software. During their training sessions, Deep Neural Net algorithms learn that the words “stop sign” go with images of many, many stop signs. Because they look at individual pixels, computer programs can be led astray by trivial variations. People can exploit this and intentionally cause a misidentification with tiny changes, called an adversarial attack.
Gary did a quick-and-dirty test by putting a peace sign on an image of a stop sign to see what a DNN would conclude. It misidentified the image as a first-aid kit. In 2018, the organizers of a machine-learning conference announced that they had accepted 11 papers proposing ways to thwart adversarial attacks like this. Three days later, an MIT graduate student, a Berkeley graduate student, and a Berkeley professor reported that they had found ways to work around 7 of these defense systems. There is clearly an AI arms race going on.

So how can thinking like a scientist possibly help a neural net work better? I talked to one to find out! “The Retinator”, Dr. Michael Abramoff, invented an autonomous AI system to diagnose diabetic retinopathy (DR), which is the leading cause of blindness in working-age adults. He said it took him decades, but he eventually succeeded in building a neural net AI system that performed as well as a doctor
So, if neural nets can be confused about stop signs, how did the Retinator keep his AI from being fooled?
His approach was to classify images of the eye the same way retinal experts do, by looking for specific signs of DR. He developed multiple detectors to look for known predictive features such as hemorrhages and other biomarkers. He also wanted his results to be comprehensible so that doctors and patients understand the diagnosis. If his system failed to recognize a case of DR, he wanted to know why it failed. He said “If I give clinicians an image with a bunch of hemorrhages, they’ll say ‘This is likely DR.’ If I start taking those hemorrhages away, eventually they’ll say ‘there’s no disease here.’” His biomarker AI system works the same
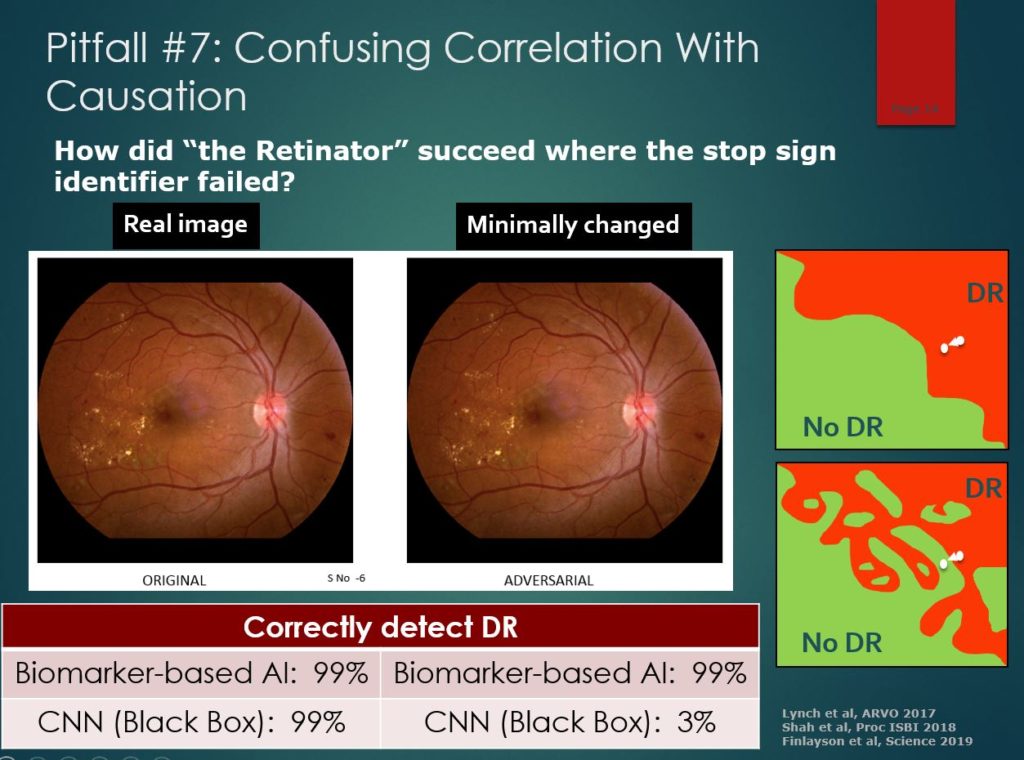
He wouldn’t settle for a black box, blank slate approach, because he knew that would risk catastrophic failure. In theory, letting computers teach themselves which characteristics are useful might find important features that clinicians didn’t know about. However, much of the data is irrelevant, so many features found to be correlated statistically with a DR diagnosis will be spurious. As with the stop sign detector, errors can arise when algorithms are put on auto-pilot. In the case of DR, there might be a bias due to the color of the retina, a different kind of background, or even part of the border around the image. A black-box model can fail with new images, with no one knowing why it failed.
Here you can see an example of a catastrophic failure of a black box algorithm. Its diagnosis is so fragile that you don’t even need a peace sign; changes in pixels that humans can’t even perceive can completely change the prediction. The Retinator’s system wasn’t tricked because it only considers the small number of features that make sense. In healthcare, the possibility of these adversarial images is particularly concerning because of the ability to make fraudulent claims by exploiting automated diagnoses.
In April 2018, Dr. Abramoff’s Idx-DR system became the first FDA approved autonomous AI diagnosis system.

Feature selection isn’t just a problem with neural nets. In 2011, Google created a program called Google Flu that used search queries to predict flu outbreaks. They reported that their model had a correlation of 0.975 with the actual number of flu cases from the CDC. Their data-mining program looked at 50 million search queries and identified the 45 queries that were most closely correlated with the incidence of flu. It was pure-and-simple data-mining. A valid study would use medical experts to specify a list of relevant query phrases in advance, and then see if there was an uptick in these queries shortly before or during flu outbreaks. Instead, Google’s data scientists had no control over the selection of the optimal search terms. The program was on its own, with no way of telling whether the search queries it found were sensible or nonsense. Google Flu may have been simply a winter detector. When it went beyond fitting historical data and began making real predictions, Google Flu was far less accurate than a simple model that predicted that the number of flu cases tomorrow will be the same as the number today. After issuing its report, Google Flu overestimated the number of flu cases by an average of nearly 100 percent. Google Flu no longer makes flu predictions.
Now I want to be clear: this type of automated data-mining is not what helped Google take over the world. It’s the thousands of rigorous A/B tests that they run that allowed them to do that. Having a huge amount of data to analyze for patterns is not enough, and Google knows that.

Compare Google Flu with how Wal-Mart stocks its shelves when a hurricane is on the way. Customers don’t just buy water and flashlights; they also buy strawberry Pop-Tarts and beer. Since historical data was analysed, this appears at first glance to be more mindless data mining. However, it is actually more like a controlled experiment! Recall that one major downside of data mining is the possibility of confounding variables. However, since hurricanes only affect a few stores out of many, Wal-Mart had a natural experiment that eliminates confounding influences like the day of the week or season of the year. This is almost as good as letting mad scientists randomly choose cities to be blasted by hurricanes and then comparing the shopping habits of the lucky and unlucky residents. The scientific method is alive and well at Wal-Mart. Another problem with data mining is that correlation can get confused with causation. It is highly unlikely that customers stocked up on Pop-Tarts in threatened cities for some reason other than the hurricanes. Also, unless buying Pop-Tarts causes hurricanes, the relationship clearly goes in the other direction. We might no know exactly why people buy these products, but we do know that hurricanes caused the increase in demand. An additional reason to believe in the Pop-tart / hurricane connection is that the association makes sense. Pop-tarts don’t have to be cooked and last practically forever. Taking advantage of natural experiments like this is something a scientists would think of.

So data doesn’t speak for itself and features don’t select themselves. Let’s shift a bit and talk about the “silent evidence of failures”. There are actually two versions of what’s called the Texas Sharpshooter Fallacy. The first one is that in order to prove what a great shot I am, I paint a thousand targets on a barn wall, fire my gun at it, and what a surprise, I hit a target! And then I go and erase all the other targets. And, of course, it’s meaningless, because, with so many targets, I’m bound to hit something… So the Texas Sharpshooter Fallacy #1 is testing lots and lots of different theories and reporting the one that seems confirmed by the data and not telling anybody that you tested many other theories. This fallacy contributes to the replication crisis in science, because there’s a publication bias towards significant findings. You’ll see the hits but not the misses.
Texas Sharpshooter Fallacy #2 is the picture here. You just fire your gun blindly at the wall and then you go and draw a target around the bullet hole and pretend that’s what you were aiming for. That’s like looking at the data and finding some coincidental little thing in there and pretending that’s what you were looking for in the first place.” I think there should be a third one, where there’s only one target, but you just keep shooting until you hit it. Then, you hide all of the bullet holes outside of the target and show what a good shot you are. This is what they call p-hacking, which is a reference to testing again and again until hitting that magical statistically significant p-value of 0.05.

Here’s a simple example: Derren Brown is a mentalist who said he could flip ten heads in a row with a fair coin. This is an astonishing claim since there is only a 1 in 1024 chance of doing that. Brown backed up his claim with a video filmed from two angles. There were no cuts in the video, it wasn’t a trick coin, and there were no magnets or other trickery involved. Is your Spidey Sense tingling?

In a later video, he gave away his secret: he had simply filmed himself flipping coins for nine hours until he got ten heads in a row. The video seemed magical, but it was a tedious trick. Brown’s prank is a clear example of how our perception can be distorted by what Nassim Taleb called the “silent evidence” of failures. If we don’t know about the failures, how can we evaluate the successes? As you develop your scientific Spidey Sense, you’ll notice that a lot of evidence starts to look like videotaped hot streaks.

So that was about interpreting evidence. Now I’d like to talk about creating compelling evidence. Suppose I want to convince you that poker is a game of skill and that you’re skeptical of my claim. Let’s say you think poker is a game of chance because the cards are randomly dealt and poker professionals often go broke. What evidence would convince you?
Well, regarding pros going broke, let me tell you about an interesting gambling experiment. Participants were given $25 and challenged to make as much money as they could in 30 minutes. They would do this by betting on a virtual coin that lands on heads 60 percent of the time. Clearly, betting on heads is a winning strategy, but how much should you bet? It turns out that something called the Kelly criterion gives an elegant answer: bet the “edge.” The edge is the difference between winning and losing chances so the edge for this game is 60–40, or 20 percent. If you bet 20 percent of your money on each flip, you can expect to make more money than you would by following any other strategy. I still remember the day Art Benjamin taught me that (he was in the audience). Most people in the study bet much more than this, and 28 percent lost all their money, even though they were winning 60% of the time. Despite the fact that the results of this experiment depend on coin tosses, I would consider this a game of skill because people who know what they are doing can expect to make more money than those who don’t. I would argue that broke poker pros are like the 28% who lost their money here. This experiment shows that betting on the right outcome is a different skill than knowing what stakes you can afford.
To create the strongest evidence that poker is a game of skill, I ran my own experiment. I predicted I could beat online poker and I put my own money on the line to prove it. I invested a whopping $50 into an online poker site and gathered data on how players respond to an immediate but small all-in bet. I downloaded the data from these experimental games and analyzed it. It turns out that people call too often. I used the data to determine which hands would win the maximum amount of money per hour assuming my opponents didn’t adjust. I called my strategy “the System”.

As you can see, when I started using the system, my opponents were no match for data science and they probably wish lucked played a bigger role in poker than it does.
This is not to say that the element of luck doesn’t shake things up once in awhile. It may not look like much on the chart, but at one point, my bankroll dropped $1800. Fortunately, I knew about the Kelly Criterion, so I never played at stakes that were so high that I could go broke. Of course, it was possible that my opponents had finally adjusted to my strategy so I analyzed the data again. I found out that it was just bad luck that had taken a bite out of my bankroll. I continued playing the System and my luck turned around as expected. By showing you results that would be exceedingly unlikely to happen by chance, now you almost have to believe my claim that poker is a game of skill. Data science isn’t just about analyzing data correctly, it’s about presenting your findings in a compelling way. And nothing is more compelling than experimental results.

You’ve waited long enough, so here are the 9 Pitfalls of Data Science. I want to you look down the list and notice something they have in common. That is that these are problems that can’t be solved by automation; they’re job security for data scientists! The Google Flu and Wal-mart Pop-Tarts stories describe different ways of analyzing historical data and show that the less mindless the approach, the better. Analysis on auto-pilot doesn’t work because data doesn’t speak for itself and up is not always up.
Similarly, the Retinator’s autonomous AI system got approved by the FDA because it was more than a black box stop sign identifier. People still have an important role in focusing computers on the features that matter.
The final take-away is that the way around the pitfalls is to follow the path of scientists. Be critical thinkers because data and features don’t always make sense. Be skeptics, because anyone can torture data until it backs them up. Be experimenters, because the strongest evidence is the evidence that could have gone against you. Put the science into data science. Be scientists.
Thank you so much for listening!
(As an Amazon Associate I earn from qualifying purchases!)